
Programmatically Capturing Software
My previous post discusses communities of practice that support software preservation and sustainability and demonstrates that software, and the source code behind it, is indeed part of our cultural heritage. Yet, preserving this material is not trivial, as source code is spread across various platforms and infrastructures, often migrating from one to another. Millions of projects, for example, are currently hosted on GitHub, GitLab, and Bitbucket. Many of these platforms have neither a long-term preservation plan nor any guarantee that they will not cease operation, as happened with Google Code and Gitorious. As a result, repositories are at risk in ways that many users do not anticipate and for which they do not (or cannot) prepare. While GitHub's Archive Program is a step in the right direction, it is, in many ways, predicated on the "set and forget" model of long-term storage of select repositories rather than long-term preservation of all repositories. In an effort to create stable archives, several projects developed solutions and workflows aimed at saving software (and its version and project histories) on Git hosting platforms. These projects have built the infrastructure needed to save software at the institutional/organization level and also on a larger scale. In what follows, I organize these efforts into three main approaches and provide examples to illustrate how each works. The first of these is the large-scale capture of event data about repositories carried out by GHTorrent and GHArchive. The second focuses on institutional/organizational solutions—put forward by the Software Archiving of Research Artifacts (SARA) initiative—that facilitate researchers self-capturing their software and scholarly outputs. The third is the effort to create a comprehensive archive of all the world’s software spearheaded by Software Heritage.
Saving Ephemera: GHTorrent/GH Archive
GitHub offers users data about hosted projects via the GitHub Rest API. This friendly API returns results in JSON format and provides information about repositories, users, issues, pull requests, watches, stars, etc. While the GitHub Rest API offers a variety of data for analysis, it also restricts the amount of data that can be retrieved and limits authenticated users to 5,000 requests per hour. In an effort to collect greater quantities of data, GHTorrent and GH Archive are two separate projects that each monitor and capture the GitHub public event timeline using the GitHub Rest API and stores it in a queryable form. Originally conceived with the Mining Software Repositories (MSR) community in mind, and developed by Georgios Gousios in 2012, GHTorrent captures all available events via the API and populates it into two databases—a MongoDB containing the raw data and a relational database (MySQL) that stores this data as links between entities. These mined data, in turn, are available to researchers and third parties who can access them through several services, which include programmatic as well as MySQL-based queries. In addition, direct downloads of data dumps are available to users. This data can be used for small scale analysis of repositories, but also can facilitate topic modeling and various visualizations, including social networks.
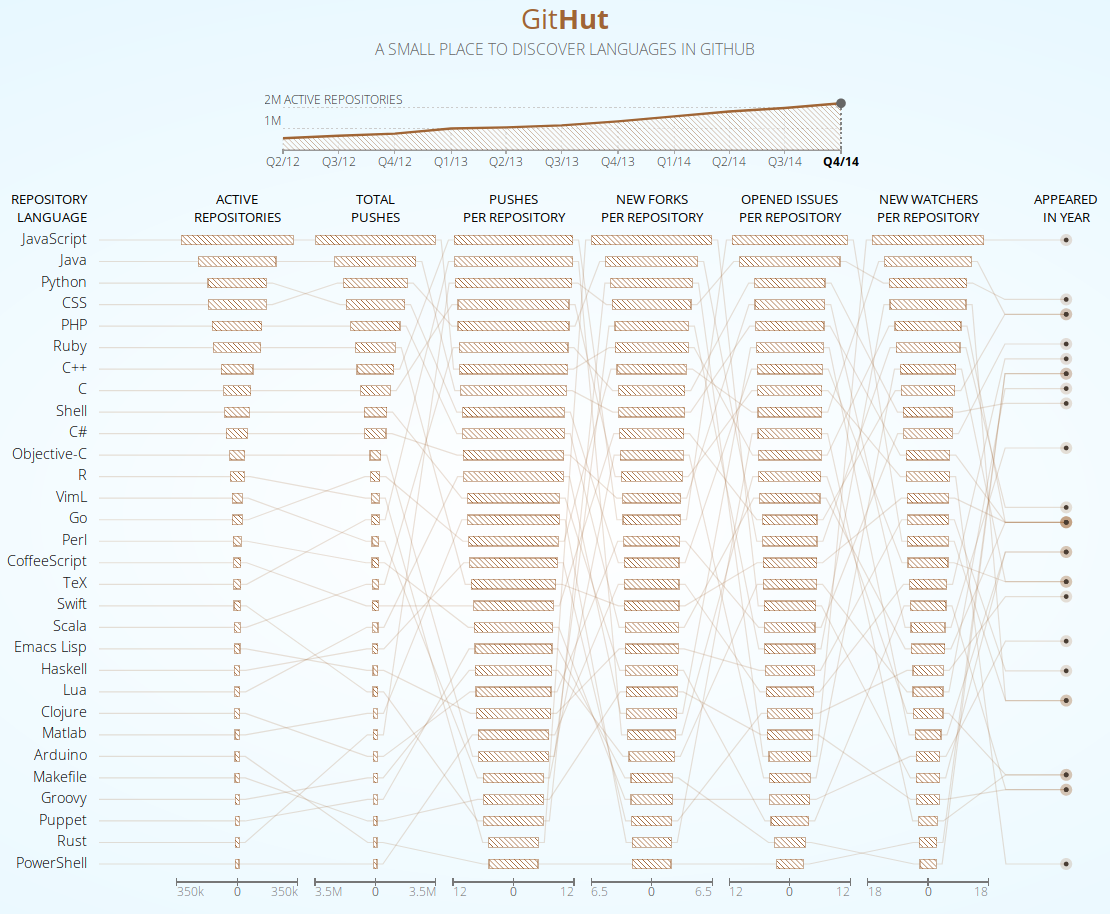
GH Archive, which was developed by Ilya Gregorik in 2011, archives over 20 GitHub events types and makes them available to users for further analysis. This data is aggregated in hourly archives that can be accessed via an HTTP client. All of GH Archive is also available as a public dataset, which is hosted on Google BigQuery and queryable via an SQL dialect. The GHArchive data on BigQuery is stored in tables organized by year, month, and day. There are many projects that have taken advantage of GH Archive, including GitHut, which "visualize[s] and explore[s] the complexity of the universe of programming languages used across the repositories hosted on GitHub."
Institutional Capture: SARA - Software Archiving of Research Artefacts
The SARA project is a joint venture between the University of Konstanz and the University of Ulm and is funded by the Baden-Württemberg Ministry of Science, Research, and the Arts. The goal of SARA is to make both research data and the software tools used to generate and analyze it available to researchers for the long-term. The project team has developed a new research service that is meant to "accompany the workflows of the researchers and enable them to capture the intermediate statuses of their research work already during the process."
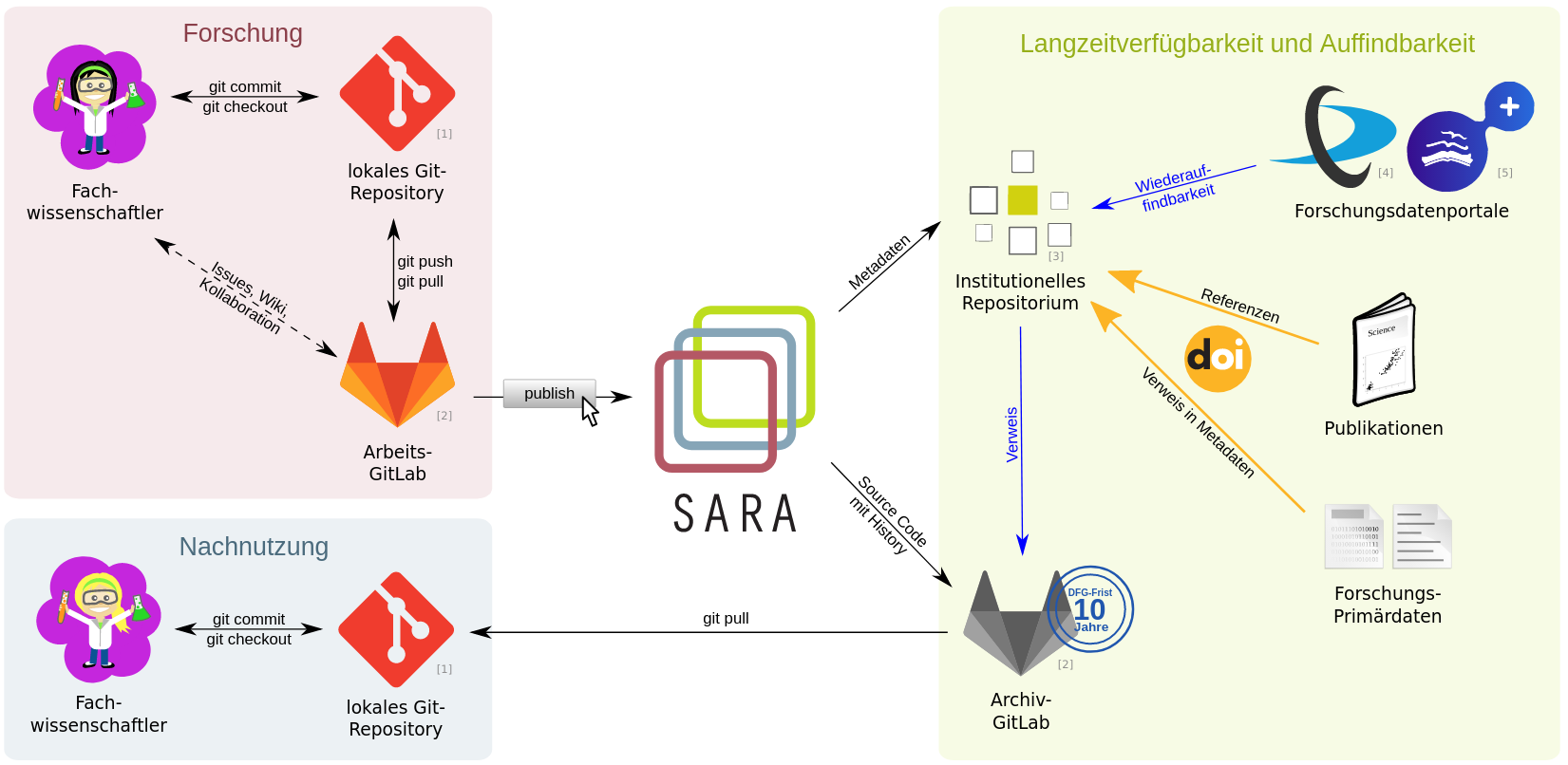
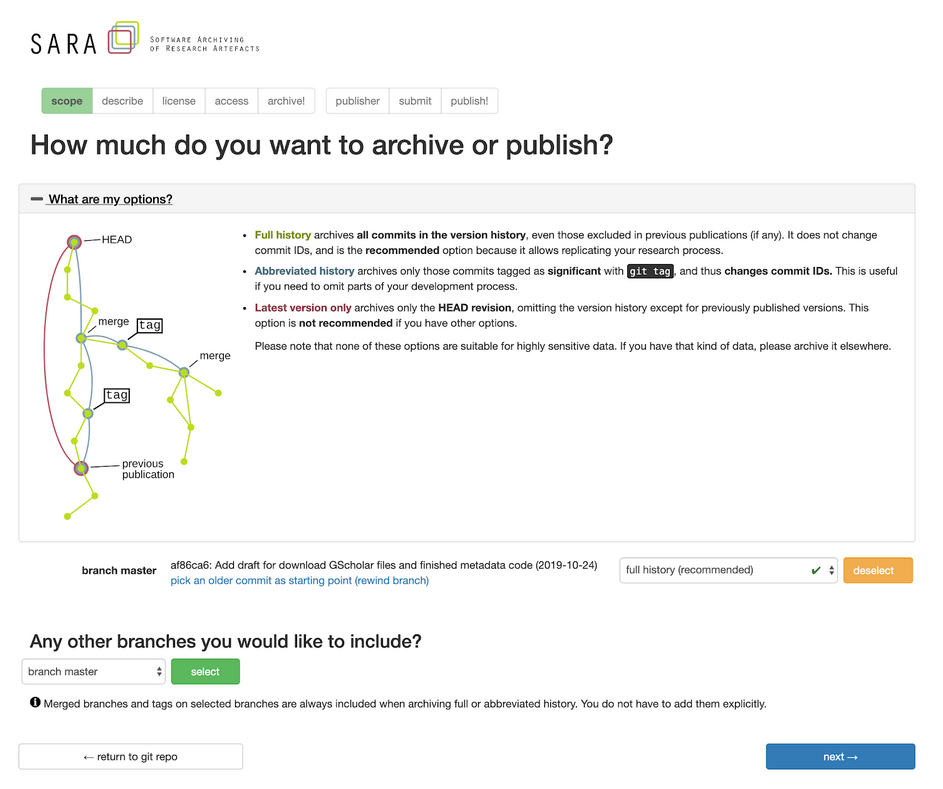
Specifically, researchers can use the SARA service to clone and ingest a copy of their research and use the metadata to create a record in an institutional repository. Currently, the project has a live demo space (https://demo.sara-service.org) where users can log into their GitLab or GitHub account, and choose the repo they would like to archive. In the SARA web interface, users provide a description, license, and access level for their repository and then archive it. Users select the part of the repository to be archived (i.e. branch master) as well as how much or little to archive or publish (full history, abbreviated history, or latest version). Any source code, along with its version history, is placed in an archival institutional instance of GitLab, maintained by the university. The source code's metadata can be used to create a publication record in an institutional repository. Currently, the SARA project supports DSpace 5 and 6, but anticipates that it can be integrated with other IRs in the future. One of SARA's key strengths is that it enables the preservation of metadata, source code, and version history and makes it possible for the data and source code to be discovered and reused by other researchers.
Saving All Source: Software Heritage
Software Heritage is an initiative launched at Inria (the French Institute for Research in Computer Science and Automation) and whose mission is foregrounded in the Paris Call, which was discussed in my last post. This organization has taken up the task of building and designing a universal archive of source code that is focused on "collecting, preserving, and sharing the source code of all the software ever written." To date, they have over 6.3 billion source code files and over 91 million individual projects, including content from Debian, GitHub, GitLab, Gitorious, GoogleCode, HAL, and many more. In turn, Software Heritage's impressive and ambitious efforts have raised awareness around software preservation in the broader digital archiving landscape and have built the infrastructure to capture, preserve, and share software for code hosting platforms.
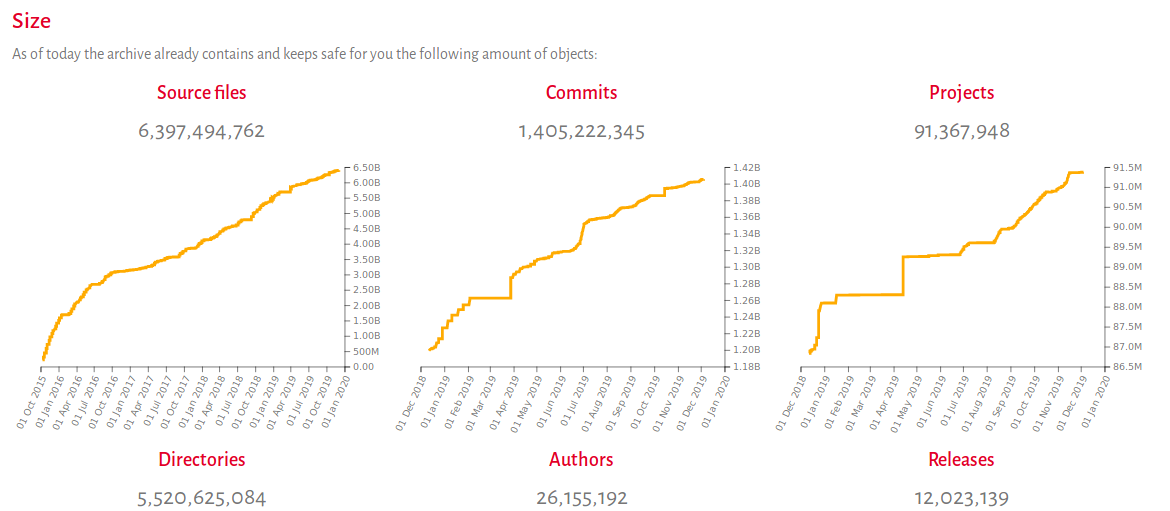
Software Heritage's collection of source code (and its development history captured by version control systems) in done by a programmatic process of listing and loading. Listers are designed for each code-hosting platform (i.e. GitHub, Debian, Cran) and "aims to produce listings of software origins and their urls hosted on various public developer platforms or package managers." Loaders, which natively deduplicate, are tasked with retrieving and ingesting versions of a given piece of software into the Software Heritage archive. As noted in Software Heritage's iPres2017 paper, "Loaders are specific technology used to distribute source code: there will be one loader for each type of version control system (Git, Subversion, Mercurial, etc.) as well as for each package format (Debian source packages, source RPMs, tarballs, etc.)." The underlying logic and data structure of Software Heritage is a Merkle Direct Acyclic Graph (DAG), which you can read more about in the iPRES 2017 paper linked above. Users can also play an active role in Software Heritage's archival process as well. Currently, the Software Heritage archive allows users to check if their repositories are in the collection. Users can also save their repositories, by using the "Save Code Now" function in the archive using the dedicated API endpoint. In addition to collecting and preserving software, Software Heritage has contributed to scholarship on Identifiers for Digital Objects as well as Saving and Citation Software in Software Heritage. Of particular interest is their use of intrinsic persistent identifiers (swh-id), which use cryptographic hashes that remain stable over time. For content, directories, revisions, and releases maintained with Git, this identifier will be identical to the Git SHA-1 hash. In turn, Software Heritage's use of intrinsic identifiers allow citation of software objects, including the repository, the file, and even specific lines of code, thus contributing to reproducibility through preservation and enhanced citation for research articles.
Implications
The approaches adopted by GHTorrent, GHArchive, SARA, and Software Heritage demonstrate how complex the mechanics and logistics of capture are, especially as they are each dedicated to related, but ultimately idiosyncratic goals. These efforts are important because effective preservation of software and its ephemera as part of the scholarly record, and our shared cultural and intellectual heritage, is a pressing matter that is becoming more and more urgent. It will take the work of both the producers of those items and the organizations dedicated to capturing them to help ensure that software and its metadata are captured for future use.
What's Next
In my next blog post, I will be exploring the last area of our environmental scan: software preservation. This area will include understanding the complexities of preserving compiled software as well as reviewing professional roles that support that work, including software curation. As noted previously, ISAGE is in active conversation about all topics in our blog posts. As I move through my environmental scan of the scholarly Git landscape in general, and of software preservation in particular, and research various archival methods including, but not limited to, web archiving, self-archiving, software preservation, etc., I invite your insights, thoughts, and recommendations for further research. You can contact me or Vicky Steeves via email or submit an issue or merge request on GitLab.
Bibliography
Abramatic, J.F., Di Cosmo, R., & Zacchiroli, S. (2018). Building the Universal Archive of Source Code. Communications of the ACM, 61(10), 29–31. https://doi.org/10.1145/3183558
Di Cosmo, R. (2019a). How to use Software Heritage for archiving and referencing your source code: Guidelines and walkthrough. ArXiv:1909.10760 [Cs]. Retrieved from http://arxiv.org/abs/1909.10760
Di Cosmo, R. (2019b, August 5). Saving and referencing research software in Software Heritage. Retrieved from Software Heritage website: https://www.softwareheritage.org/2019/08/05/saving-and-referencing-research-software-in-software-heritage/
Di Cosmo, R., Gruenpeter, M., & Zacchiroli, S. (2018). Identifiers for Digital Objects: The Case of Software Source Code Preservation. IPRES 2018 - 15th International Conference on Digital Preservation, 1–9. https://doi.org/10.17605/OSF.IO/KDE56
Di Cosmo, R., & Zacchiroli, S. (2017). Software Heritage: Why and How to Preserve Software Source Code. IPRES 2017 - 14th International Conference on Digital Preservation, 1–10. Retrieved from https://hal.archives-ouvertes.fr/hal-01590958
GH Archive. (n.d.). GH Archive. Retrieved from GH Archive website: https://www.gharchive.org/
GHTorrent. (n.d.). Retrieved November from GHTorrent website: http://ghtorrent.org/
Gousios, G., Vasilescu, B., Serebrenik, A., & Zaidman, A. (2014). Lean GHTorrent: GitHub Data on Demand. Proceedings of the 11th Working Conference on Mining Software Repositories, 384–387. https://doi.org/10.1145/2597073.2597126
Gruenpeter, M. (2018). Software preservation: A stepping stone for software citation. Retrieved August 9, 2019, from Software Heritage website: https://www.softwareheritage.org/2018/06/25/software-preservation-for-software-citation/
Institut national de recherche en informatique et en automatique. (2019). Paris Call: Software Source Code as Heritage for Sustainable Development. Retrieved from https://unesdoc.unesco.org/ark:/48223/pf0000366715.locale=fr
SARA - Software Archiving of Research Artefacts. (n.d.). Retrieved from https://www.sara-service.org/
Software Heritage. (2018). Browsing the Software Heritage archive: A guided tour. Retrieved from Software Heritage website: https://www.softwareheritage.org/2018/09/22/browsing-the-software-heritage-archive-a-guided-tour/
Squire, M. (2017). The Lives and Deaths of Open Source Code Forges. Proceedings of the 13th International Symposium on Open Collaboration - OpenSym '17, 1–8. https://dl.acm.org/citation.cfm?doid=3125433.3125468