Self-archiving is the act of depositing a copy of a digital object in a repository so that it is openly accessible to researchers and the public free of charge. While theses, dissertations, pre- and post-prints, and other text-based manuscripts often dominate the literature on self-depositing, datasets and software also have a place within this discourse. As part of the Open Access (OA) model, self-archiving in an open repository is considered "Green" Open Access, while "Gold" Open Access is publishing in a fully OA or a hybrid journal (cf. Harnad, et al., 2008; Harnad, 2015). This blog post discusses options available to self-archive source code so that it is openly available and citable. I begin with a discussion of the problem of source code citability. I then discuss solutions to this including integrations between source code hosting platforms and repositories, the open-access repository Zenodo, and the collaborative workspace Open Science Framework (OSF). Institutional Repositories (IRs) offer yet another option for preserving works and making them discoverable. I will discuss them in my next blog post and will limit this posting to non-IR options.
When scholars, or others, create source code they wish to share an issue immediately arises. Where can this be placed so that it is both safe and openly available? More and more, they turn to services like GitHub. While this works well for making the source code available, it does not necessarily meet all of the needs a scholar may have. For example, properly citing source code as an academic output—and thus giving and receiving proper credit and acknowledgment for that work—is not an intrinsic part of source code hosting services.
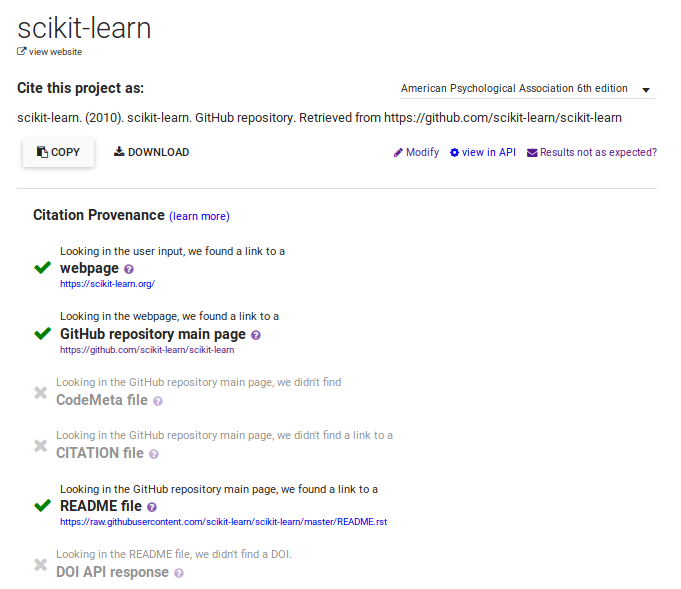
While extremely valuable for version control, GitHub, BitBucket, SourceForge, etc., are not expressly concerned with citation. According to the Software Sustainability Institute's Software Deposit: Guidance for Researchers, these platforms are not optimal for long-term preservation because they do not provide DOIs, depend on URLs which can break, and there is no promise that they will remain solvent. That institutional-level preservation is not a key concern is not surprising as these sites make no guarantees about the accuracy, safety, or functionality of the code hosted. GitHub, for example, makes it clear in its Terms of Service that individuals using the service do so at their own risk. The ToS state "we provide our service as is, and we make no promises or guarantees about this service" and "we will not be liable for damages or losses arising from your use or inability to use the service or otherwise arising under this agreement." In other words, services like GitHub makes no promises as to the longevity of the service. While providing a great deal of latitude to all users, this approach is not conducive to the kinds of discovery and citability that scholars, and their home institutions, require.
In a green paper written for the Software Sustainability Institute, Michael Jackson (n.d.) discusses the important issue of citing and describing software, especially when it has had an impact on research, and makes several recommendations that were available circa 2012 (i.e. using footnotes/appendices, DOIs, URLs, in-text description, etc). Jackson puts software citation in the larger context of the important role of software in research, including publishing software in a persistent and citable way, having software available for the long term, acknowledging software as a research output, and, importantly, "ensuring that developers of research software have their contributions recognized and rewarded" (Jackson, n.d.). In 2016, the Force11 Software Citation Working Group released the Software Citation Principles to provide a consistent policy for software citation across disciplines and argued that software should be "a citable entity in the scholarly ecosystem." Inconsistent citation methods for software in academic papers were a driving factor behind the creation of these principles, which suggest basic metadata for different use cases (i.e. publishing a software paper). All use cases assume a citable software object, meaning all software should have a DOI and metadata should be included in a plain text CITATION file or machine-readable CITATION.jsonld file (Smith, et al., 2016).
As Jackson's paper, the Software Sustainability Institute, and the work of Force11 makes clear, one of the ways to address the matter of citability is the use of a Digital Object Identifier (DOI). DOIs are an important way to locate and cite digital objects. When it comes to software, which often has multiple versions, this is particularly important for research, reuse, and reproducibility. The DOI system is an ISO standard format in which a DOI "is permanently assigned to an object to provide a resolvable persistent network link to current information about that object, including where the object, or information about it, can be found on the Internet." When it comes to software, which often has multiple versions, DOIs are particularly important for research, reuse, and reproducibility. The use of DOIs has been adapted to accommodate versioning so that each iteration is associated with its own DOI, which persistently points toward that version. Recently, repositories like Zenodo (discussed in more detail, below) have implemented DOI versioning (read about Zenodo's implementation here). DOI versioning is a critical component for accurately citing a specific software version. In addition to versioning for software, metadata standards and crosswalks for describing software have been developed to improve citations and description. CodeMeta, a schema for JSON-LD, is "a concept vocabulary that can be used to standardize the exchange of software metadata across repositories and organizations" (CodeMeta, n.d.). Additionally, there is the Citation File Format (CFF)—"a human- and machine-readable file format in YAML 1.2 which provides citation metadata for software." The creation of these formats is to simplify "the crosswalk between the wide variety of metadata standards for software, and is increasingly integrated into DOI registration workflows" (Fenner, Katz, Nielsen, & Smith, 2018).
These software citation standards are used by one service, CiteAs, which "uses a pattern of web-based searches to try to discover and represent the best way to cite a given scholarly artifact" (CiteAs, 2017). Given a URL to a software repository, CiteAs looks for either a CFF file, a CodeMeta file, or other free-text information in a README. file or language-specific file (like an R description file) to display the correct citation to the user. If none of those exist, CiteAs will derive citation information from the repository itself and display it to the user. Information for how they interact with their sources is listed out in non-technical language on their sources page. What's more, is the process for deriving that citation is also visible, which empowers users. There's no black box; the information and decisions that CiteAs makes/uses is transparent to the users. This is a great example of how citation standards can be used to improve the way that scholars credit each others' works.
The need to accurately cite source code, and the recognition of the various constraints regarding this process entailed with the use of hosting services, has given rise to several platform integrations. Some elements of these partnerships have evolved over the past few years, and some have only recently come to fruition. For example, there is a GitHub and Figshare integration, which allows for source code repositories to be synced (Hyndman, 2016). This integration is the result of a collaboration between the Mozilla Science Lab, Figshare, and GitHub and allows academics to leverage the integration in two ways: to pull releases in from another account and use a browser extension which can be activated at any GitHub repository, producing a DOI (Summers, 2014).
Next in this post I'll cover two other platform integrations in greater depth: GitHub <> Zenodo, and Bitbucket, GitLab, and GitHub <> the Open Science Framework. The recent integrations provide excellent examples of responses to this issue of citation.
Zenodo is an open access/open repository that allows researchers to share publications as well as data, software, video/audio files, visualizations, and datasets. It was first created as part of the Open Access Infrastructure for Research Europe (OpenAIRE) project, a pioneer in the open data movement in Europe and also who provided a multi-purpose repository for projects funded by the European Commission (Zenodo, n.d.). The impetus to create Zenodo, which launched in 2013 and is hosted at CERN, was to support open access across European institutions and, later, for research data management (RDM) (European Commission, 2017). Since it was first founded, Zenodo has been successful in attracting a variety of researchers, institutions, users, platforms, and publishers largely because it allows for collaboration while work is still ongoing and supports "collaboration and knowledge diffusion" worldwide (European Commission, 2017). While data is certainly a major focus, Zenodo also foregrounds the importance of access to analytical source code, whose absence would make it "very difficult or even impossible to interpret [data]" (CERN, 2016). As a result, Zenodo "makes the sharing, curation, and publication of data and software a reality for all researchers" (Zenodo, n.d.). With every submission to its repository, Zenodo provides a DOI (Digital Object Identifier), allowing for easier citation of data and software.
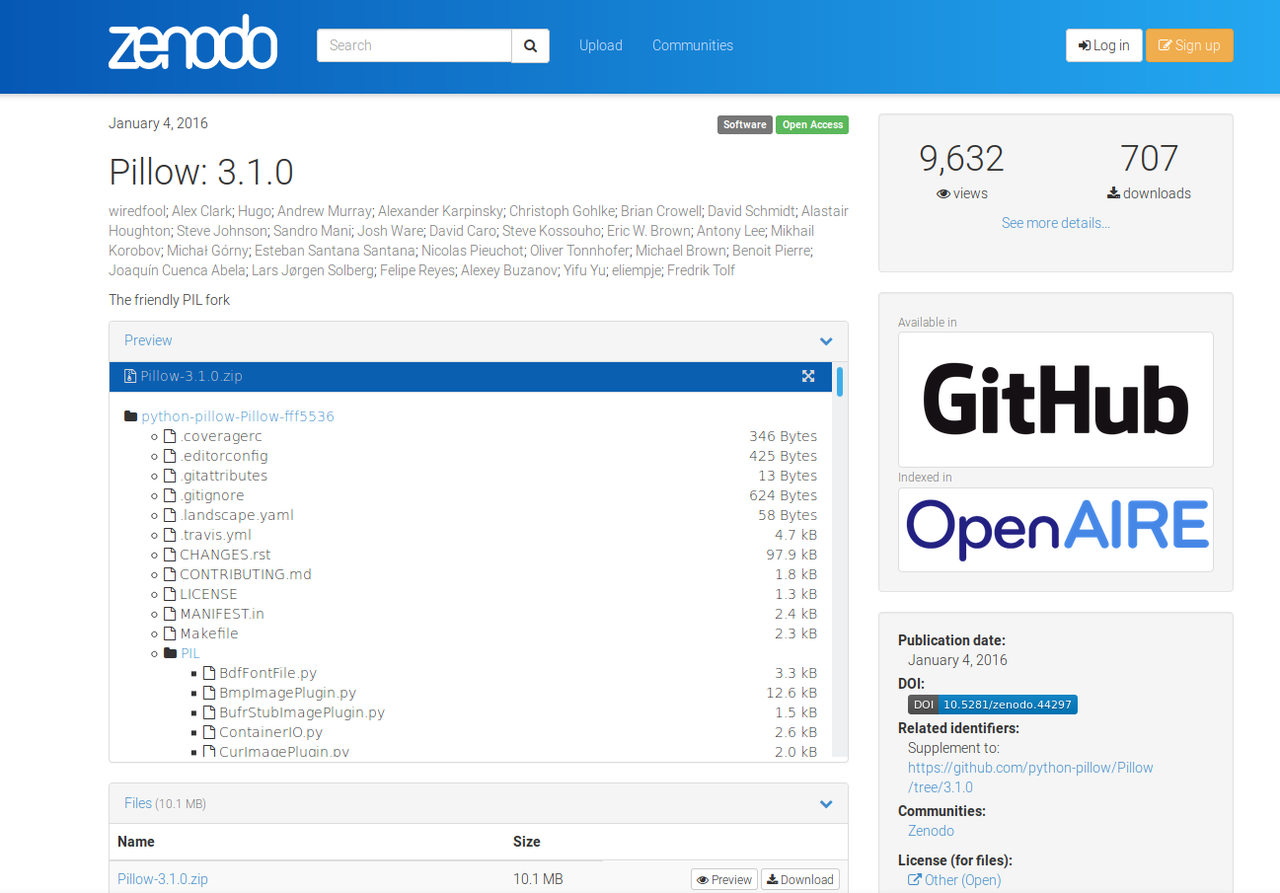
GitHub integrated with Zenodo in 2014 and was updated in 2016. This configuration merges a version-control development platform (GitHub) with a well-regarded CERN-hosted repository. As stated in the European Commission's Impact Case Study on Zenodo, the GitHub-Zenodo integration has been "a major step forward by allowing any software package on GitHub to be given a digital object identifier (DOI), enabling the sharing and preservation of software, and attracting researchers who are familiar with open-source methodology." This type of integrations seemed to have a resounding effect on DOIs produced for software. In a 2018 blog post, DataCite examined DOI registrations for software and found that the number of DOIs created has grown rapidly since 2014. It also found a correlation between growth rates of DOIs for software as well as the 2014 announcement of the GitHub-Zenodo integration and the announcement/advertisement of the 2016 upgrades to Zenodo, which included improvements to the GitHub Integration.
As of May 2018, the leading sites for creating DOIs were Zenodo (41,346) followed by Figshare (4,226) and the National Cancer Institute's Bioconductor (2,769), an open-source software repository for bioinformatics (Martin, et al., 2018). As of this post (July 2019), these numbers have grown: there are currently 98,631 DataCite DOIs for registered software, the majority coming from Zenodo (81,551) and Figshare Academic Research System (6,469). These types of integrations—along with innovations such as the Citation File Format, CodeMeta, CiteAs, and Software Heritage—will likely contribute to the continued rise of DOIs for software (Martin, et al., 2018). These integrations nicely address the issue of citability, noted above. This is only part of the issue, however. For source code to be discoverable, retrievable, and citable it must be properly preserved, ideally in multiple locations. As stated in the Software Sustainability Institute's Software Deposit Guidance for Researchers makes clear, individuals should take the extra step to submit a URL to their software to the Software Heritage Foundation, which is "an international initiative to provide a universal archive and reference system for all software." Using this URL, Software Heritage will continuously pull a copy of the source code into their archive.
While the integrations discussed above are important contributions towards acknowledging software as a research output and have made a large impact on DOIs minted for software, they do not currently support the entirety of a research lifecycle—in large part because researchers, academics, and scientists tend to use many platforms for a single project. One of a suite of products from the Center for Open Science, the Open Science Framework is a workflow platform for researchers to register, design, share, and collaborate on a project throughout its lifecycle. This approach to the complexities of preserving information and making it available for use and reuse expands on the functionality offered by the integrations discussed above by offering a project management layer and the availability of a multitude of add-ons. The OSF can connect to many disparate services, allowing a researcher to share one link to a project space that contains code (GitHub, GitLab, or Bitbucket), data (S3, Dataverse, Figshare, One Drive, Google Drive, Box, Dropbox), citations (Mendeley, Zotero), and documentation (in the OSF wiki space) (Steeves, 2018). The OSF also allows for multiple contributors (with different permission levels) and each user, component, project, and file is given a unique URL; public projects are given DOIs and archival resource keys (ARKs) and OSF has a built-in version control system (Foster & Deardorff, 2017).
The approaches discussed in this post offer scholars and the scholarly community options for self-archiving source code. Each has its benefits and limitations, which is not surprising given how complex the scholarly landscape is—something my colleague Sarah Nguyen discusses in her posts for the IASGE project. The increased use of DOIs as a means of adding stability and regularity to how software is cited has been an important response to the need to locate and preserve software, make it accessible, and ensure that its authors receive the recognition they deserve. Self-archiving is an important act by those wanting to participate in the open landscape and draws upon data/software sharing principles, all which help ensure greater reproducibility.
Since the Investigating and Archiving the Scholarly Git Experience (IASGE) project is concerned with institutional-centered archiving, I will be discussing the pros and cons of IRs—as well as proposed options for breaking away from the traditional IR model—in my following blog post. ISAGE is in active conversation about all topics in our blog posts. As I move through my environmental scan of the scholarly git landscape in general, and of software preservation in particular, and research various archival methods including, but not limited to, web archiving, self-archiving, software preservation, etc., I invite your insights, thoughts, and recommendations for further research. (Please note that our interest surrounding self-archiving in IRs is software agnostic, however, insights into this area are welcome.) You can contact Vicky Steeves and me via email or submit an issue or merge request on GitLab.
CERN. (n.d.). Zenodo | CERN and Society Foundation. Retrieved from https://cernandsocietyfoundation.cern/projects/zenodo
CiteAs. 2017. Impactstory, 2019. GitHub, https://github.com/Impactstory/citeas-webapp
Druskat, S. (n.d.). Citation File Format (CFF). from Citation File Format (CFF) website: https://citation-file-format.github.io/
European Commission. (2017). Open Science Monitoring - Impact Case Study Zenodo. Retrieved from https://ec.europa.eu/research/openscience/pdf/monitor/zenodo_case_study.pdf
Fenner, M., Katz, D. S., Nielsen, L. H., & Arfon, S. (2018). DOI Registrations for Software [Website]. Retrieved July 8, 2019, from DataCite Blog website: https://blog.datacite.org/doi-registrations-software/
Foster, E. D., & Deardorff, A. (2017). Open Science Framework (OSF). Journal of the Medical Library Association: JMLA, 105(2), 203–206. doi:10.5195/jmla.2017.88
GitHub. (2016). Making Your Code Citable · GitHub Guides. Retrieved from https://guides.github.com/activities/citable-code/
Harnad, S. (2015). Open access: what, where, when, how and why. In Holbrook, J. Britt and Mitcham, Carl (eds.) Ethics, Science, Technology, and Engineering: An International Resource. Farmington Hills MI, US. Macmillan Reference.
Harnad, S., Brody, T., Vallières, F., Carr, L., Hitchcock, S., Gingras, Y., Oppenheim, C., Hajjem, C. & Hilf, E.R. (2008). The Access/Impact Problem and the Green and Gold Roads to Open Access: An Update, Serials Review, 34:1, 36-40, DOI: 10.1080/00987913.2008.10765150
Hyndman, A. (2016). figshare launches revamped GitHub integration. Retrieved from https://figshare.com/blog/figshare_launches_revamped_GitHub_integration/243
Jackson, M. (n.d.). How to cite and describe software [blog post]. Software Sustainability Institute. Retrieved fromhttps://www.software.ac.uk/how-cite-software
Jackson, M. (2018). Software Deposit: Guidance for Researchers. https://doi.org/10.5281/zenodo.1327310
Open Science Framework. (n.d.A). FAQs. Retrieved from OSF Guides website: http://openscience.zendesk.com/hc/en-us/articles/360019737894-FAQs
Open Science Framework. (n.d.B). OSF Guides. Retrieved from http://help.osf.io/
Smith, A. M., Katz, D. S., & Niemeyer, K. E. (2016). Software citation principles. PeerJ Computer Science, 2, e86. https://doi.org/10.7717/peerj-cs.86
Software Heritage. (2019). You can "save code now"! Retrieved from https://www.softwareheritage.org/2019/01/10/save_code_now/
Software Sustainability Institute. (2018). Checklist for a Software Management Plan. https://doi.org/10.5281/zenodo.2159713
Steeves, V. (2018). University of Utah 2018 Reproducibility Immersive Course. Retrieved from https://vickysteeves.gitlab.io/2018-uutah-repro/the-open-science-framework.html
Summers, N. (2014). Mozilla Science Lab, GitHub and Figshare Fix Code Citation in Academia. Retrieved July 15, 2019, from The Next Web website: https://thenextweb.com/dd/2014/03/17/mozilla-science-lab-github-figshare-team-fix-citation-code-academia/
Zenodo. (n.d.). About Zenodo. Retrieved from https://about.zenodo.org/
Zenodo. (2017). Zenodo now supports DOI versioning! Retrieved from https://blog.zenodo.org/2017/05/30/doi-versioning-launched/