Although primarily used to capture material related to cultural heritage, politics, and social media, web archiving tools and techniques can be leveraged to capture source code in ways that allow for downloading repositories similar to the live web. The question is how can we extend web archiving to capture code and its ephemera in a manner that most fully reflects the scholarly git experience?
For this blog post, I will cover three examples of state-of-the-art web archiving techniques—Archive-it, Heritrix, and Webrecorder—and will explore some examples in which members of the web archiving and software preservation communities have used web harvesting tools to capture software and content from git-hosting platforms. The web archiving tools explored in this post have been chosen in particular because they are popular among academic libraries for external (subscription-based) and local (in-house) captures, as indicated in the NDSA 2017 Survey of Web Archiving in the United States (Farrell, McCain, Praetzellis, Thomas, & Walker, 2018).
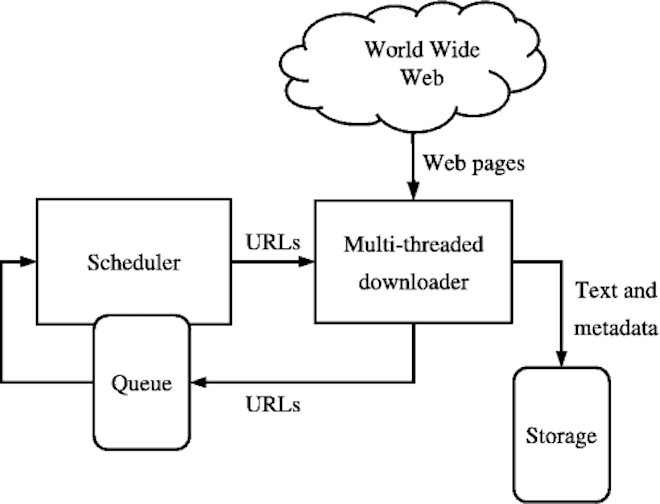
The most common tool for aggregating and archiving web content is with a crawler—also known as a robot or spider—which indexes and saves information hosted on the web. Akin to search engine software, a list of URIs (called a seed list) is given to the crawling software; the software contacts the web servers indicated in the list, retrieves and stores the requested pages and its elements, and moves to the next set of URIs (Brügger, 2018). Web crawlers, in general, are scalable, automatic, and tend to be content agnostic, allowing for the collection of both developer-facing and public-facing content. For instance, crawlers collect and save the HTML/CSS code that comprise a website. Additionally, the rich content of websites are also saved, including embedded material such as images, word documents, pdfs, videos, and audio files as well as HTML. All this material is organized into “content blocks” and saved as an aggregated WARC file. This file type, which was created at the Internet Archive, was adopted as an ISO standard in 2009 (Bragg & Hanna, 2013) and is the Library of Congress preferred preservation file format for preserving websites.
Currently, the International Internet Preservation Consortium (IIPC) provides a comprehensive list of web archiving software used to acquire web content. In addition, a tools and services section is available in the 2017 NDSA Web Archiving in the United States Survey. The tools and software linked from these resources range from stable to in-development, and from simple to complex crawlers and management tools. The ideal tools and services for an institution will vary by need and interest. Interoperability and current/anticipated preservation workflows, however, should be considered in addition to staffing, technical requirements, and administrative oversight of a web archive.
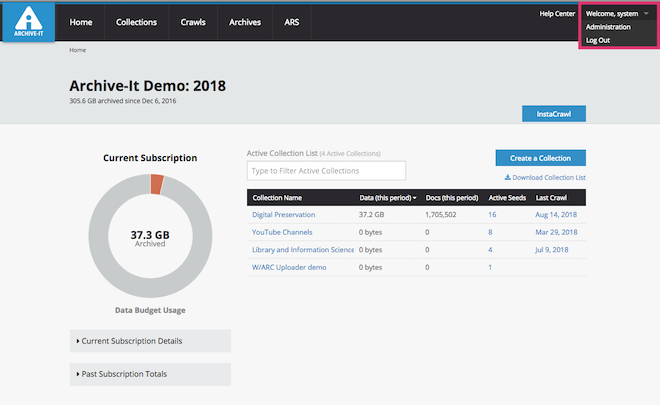
The most prevalent tool used by cultural institutions and academic libraries for web archiving is Archive-It, a subscription-based service that “helps organizations to harvest, build, and preserve collections of digital content” (Archive-It, 2014). Archive-It is a partly open source tool, relatively all inclusive, and requires no programming or custom-built software. As a result, Archive-It is advantageous for institutions that have a small staff or no dedicated developer(s) on the project. The Archive-It administrative web application (WUI) allows web archivist, technicians, and staff to schedule crawls, review crawl reports, add seed URIs and scoping rules, and patch crawl missing content. It also allows users to schedule test crawls, which can be used to gauge a larger crawl and modify scoping rules and seeds if necessary. Archive-it provides technical support services and offers application training via synchronous and asynchronous webinars. As part of the subscription, a public-facing website, that displays archived sites via the Wayback Machine, allows visitors to browse and search the public collections of partners by date of capture and full-text search (Dooley & Bowers, 2018). For institutions looking to preserve multiple copies of their WARC files, Archive-It can sync a backup copy to DuraCloud. As noted by digital archivists Antracoli, Duckworth, Silva and Yarmey (2014), this feature, along with the available technological support, is often a determining factor when deciding on Archive-It over other web archiving technologies.
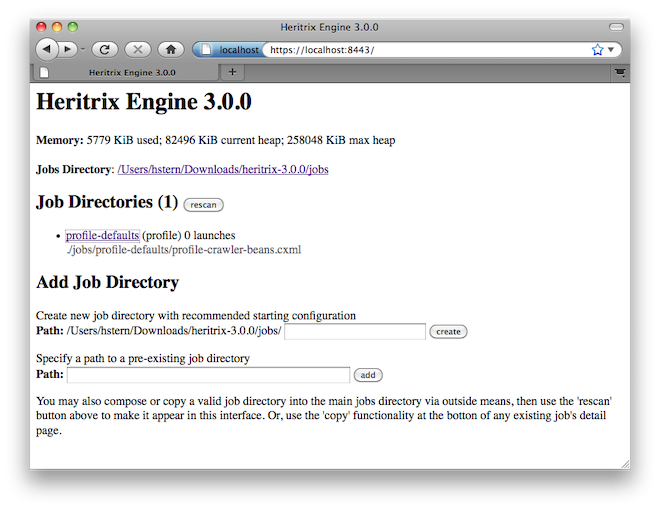
Heritrix is a free and open-source, extensible, archival-quality web crawler developed by the Internet Archive. First released in 2004, Heritrix is written in Java and is available under an Apache 2.0 license. Interaction with Heritrix is possible through a browser or through a series of command line tools. Running Heritrix requires a Linux distribution, a Java Runtime Environment, a list of dependencies, and a suitable amount of RAM. The most recent version is 3.4-Y, where Y represents the date of the latest update. This new release of Heritrix 3 is made possible by the team at the UK Web Archives, in coordination with the Internet Archive, who have been hard at work fixing some serious bugs and adding new features to Heritrix (Jackson, 2019).
There are three main modules to Heritrix—the Crawl Scope, the Frontier, and the Processing Chains. The Crawl Scope refers to the list of URIs (or seeds) included in the crawl and indicates to which level beyond the main domain is “out of scope.” The Frontier refers to the state of the crawl and tracks which URIs have already been captured and which are scheduled to be captured. The Processing Chain is a 5-step process moving from pre-fetch (i.e. scheduling), to fetch, extract, index, and finally to post-processing. In general, using Heritrix requires a strong programming and/or developer background and familiarity with the command line. Heritrix is the underlying crawler for Archive-It and, with Umbra, which helps Heritrix render content as if in a browser, saves crawled content to WARCs for Archive-It subscription partners (Lohndorf, 2018). The Institutions that use Heritrix are wide ranging. After the crawler Alexa, Heritrix is now the leading crawler at the Internet Archive, and is the software used for both Archive-It Services and the Wayback Machine. The British Library’s Domain Research Project, the UK Web Archives, the Danish Netarchive.dk, the Library of Congress Web Archives, the National Library of New Zealand Web Curator Tool, and CiteSeerX all use Heritrix for their various endeavors and web archiving needs (For full list, see Heritrix, 2019).
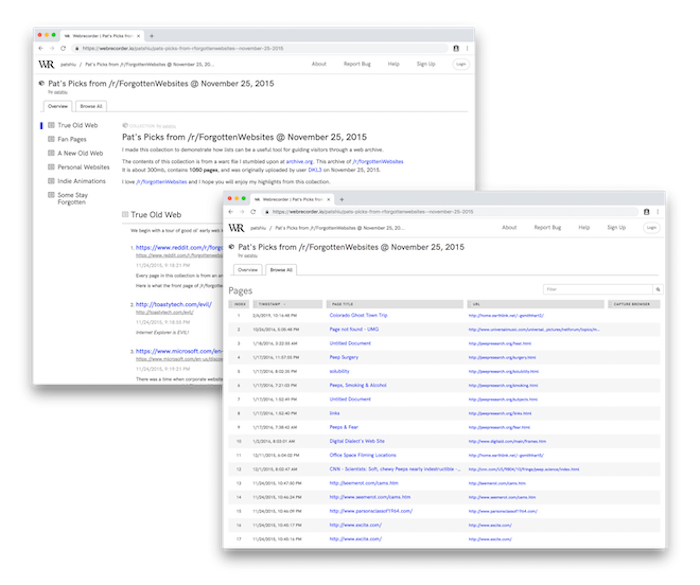
In contrast to medium-to-large scale crawlers such as Heritrix, Rhizome’s Webrecorder allows for “intricate websites, such as those with embedded media, complex Javascript, user-specific content and interactions, and other dynamic elements, to be captured and faithfully restaged” (Rhizome n.d.). The Webrecorder web application, which was recently streamlined, is especially intuitive and well-designed, letting users create collections and browse captured content and collections quite easily. To capture a website, a “Session” can be initiated with a single URI and, through a user’s interaction with a page, similar to natural browsing, scrolling, and clicking through hyperlinks, content is recorded and saved. Any content missed during a Session can be captured through a patch crawl and Sessions can be made public or private. Recently, Webrecroder has released several innovative features and toolsets. This includes an “autoscroll” button located in the Sessions page, which allows easier capture of “infinite scroll” websites, such as social media sites like Twitter, Instagram, and Tumblr. In June 2019, Webrecorder introduced Browsertrix—a browser-based crawling system for “orchestrating Docker-based Chrome browsers, crawling processes, behavior systems, web archiving capture and replay, and full-text search.” With these types of improvements, especially concerning the capture of dynamic content, it is not surprising that there has been an increased use of Webrecorder in the past several years, as highlighted in the NDSA 2017 Survey of Web Archiving in the United States. Many institutions are incorporating Webrecorder into their web archiving workflow and it is often used in tandem with another crawler—such as Archive-It or Heritrix, indicating that institutions are diversifying their web archiving toolkit to more successfully capture different types of content (Farrell, McCain, Praetzellis, Thomas, & Walker, 2018).
While predominantly used to create thematic collections on a particular subject or to capture cultural heritage material, web archiving tools and harvesting technologies are not necessarily limited to only these tasks. A few examples of using crawlers to capture software and source code will demonstrate this. Three in particular provide case studies for the feasibility of capturing and preserving source code and its ephemera for future use. John Gilmore’s Archive-It Collection can be seen as an initial foray into this topic. More contemporary and state-of-the art versions include the scholar-focused project titled "Towards a Web-Centric Approach for Capturing the Scholarly Record" being carried out by the Las Alamos National Laboratory and the large-scale software-centered efforts of the Software Heritage archive.
Within Archive-It’s publically available collections, there are some institutional partners who currently collect, or have collected, source code and software. Of particular interest is the Archive-It Collection created by John Gilmore, the co-founder of the Electronic Frontier Foundation. Gilmore joined Archive-It in 2007 as its first individual member and three of his collections—Bitsavers old computer and software, Free and Open Source Software, and SourceForge free software collection—actively collect ephemera about source code, programming and computer manuals, and thousands of source code files. While many of the collections are incomplete, and are in need of QA, there are several instances where legacy source code, especially from the Bitsavers old computer and software collection, could be viewed and downloaded from the archived page.
While a move in the right direction, these collections were not designed to capture scholarly information with a high degree of accuracy. The Los Alamos National Laboratory Library project titled "Towards a Web-Centric Approach for Capturing the Scholarly Record" is making efforts to fill that gap. The development team begins with the premise that researchers are using a variety of platforms (Git, Publons, Wikipedia, Slideshare, Wordpress, etc.) to house their scholarly artifacts. They note that this presents a few key problems: institutions are not aware that researchers are using various platform and if they do know, they do not know which ones in particular. Further, institutions do not currently have copies of these artifacts, and that the use of these external sites tends to decrease the use of institutional repositories. In addition, the team also note that the platforms involved are not necessarily focused on preservation or on ensuring scholarly communication. For the Los Alamos team, the best solution for what they see as an institutional problem is for institutions to take the lead on identifying, tracking, and archiving scholarly artifacts. They argue that institutions are not only well-suited to this task but also that the have vested interests in intellectual property issues attached to research activities, have longer “shelf-lives” than other types of organizations and are thus more stable, and that archiving scholarly output aligns with the spirit and mission of the academic library.
In order to capture scholarly work with a high level of fidelity, the Los Alamos project employs a workflow that centers on a “pipeline” that tracks, captures, and archives artifacts. To date, they have completed a small scale test with 16 participants who are tracked using ORCID IDs and handles. The project employs algorithms to check each platform (using its API) to see if new content is available for each of the participants. If any new content has been added to the site, it is captured and is logged. Each capture generates a WARC file, which can be archived and played back through Webrecorder Player. For this system to produce a high-quality archive, the team also has realized that a simple capture would not suffice. They understand that one of the key issues with a well-functioning archive is that its scope, or boundary, must be reasonable. To that end, Los Alamos National Laboratory and the Web Science and Digital Library Research Group of Old Dominion University have introduced a tool called Memento Tracer, which allows an archivist to determine which elements are vital to capture each time the site is crawled. The traces record the archivist’s interactions with the page--her or his ‘clicks’ to get to desired elements--and stores them in a JSON file for later playback. The tracer function not only scopes a particular site but also can be used to perform the same functions for all entries of a particular type--e.g. It can automate the process of capturing the same types of information from sites with similar layouts (e.g. GitHub). A demonstration of this for a Github repository is available at: http://tracer.mementoweb.org/demos/github/
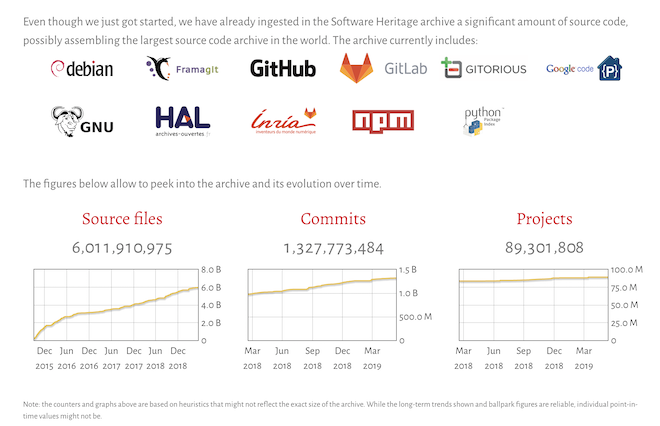
By harvesting the web, the crawlers discussed above capture information in a manner that ideally makes it possible to reproduce the look and feel of the original page. Most crawlers were designed to capture more traditional web content, such as text, images and certain embedded files and not for capturing material from git hosting platforms or source code itself. One organization in particular, Software Heritage, has focused on foregrounding the importance and value of source code and has built several crawlers to capture it in ways that are quite distinct from web archiving. The crawlers, which are divided into "listers" that list all software on a given forage and "loaders" that retrieve all versions of a given piece of software, and add them to the Software Heritage archive. This is just one component of the Software Heritage stack. Another interesting component is the "swh-indexer" which is tasked with locating objects, extracting metadata from those objects, and storing that information in the swh-indexer database. According to the documentation, the current indexer can detect the encoding and mimetype, detect the programming language of a file in a repository, compute tag information and license, and capture metadata. Currently, Software Heritage is able to capture an array of different code hosting platforms and currently captures and preserves source code from GitHub, GitLab, Debian, Google Code, HAL, and Gitorious. Indeed, Software Heritage does not capture the types of information that would make it possible to recreate the original web page on which the source code appeared. Instead, they draw upon an important clarity of focus found in the Unix Philosophy and foreground source code. While Software Heritage actively saves source code, users can also deposit software, and developers are able to utilize the dedicated API endpoint to push software to Software Heritage. To date, Software Heritage has collected over 89 million projects, and over 6 billion source code files.
These projects demonstrate that current state-of-the-art technologies allow for the capture, and preservation, of web content. These range from crawling large amounts of web URIs (Archive-It), to innovative workflows (Los Alamos), to bespoke software (Software Heritage). As these types of crawlers are increasingly becoming part of the preservation workflow of institutions, governmental agencies, academic libraries, and museums, the research questions asked by the Investigating the Scholarly Git Experience project as well as the issues raised and explored by the Los Alamos project point to important themes and topics that must be addressed. Namely, how can we underscore that source code is also part of scholarly record and highlight the potential—and importance—of also capturing it and its ephemera with these increasingly sophisticated tools?
Abramatic, J.-F., Di Cosmo, R., & Zacchiroli, S. (2018). Building the universal archive of source code. Communications of the ACM, 61(10), 29–31. https://doi.org/10.1145/3183558
Antracoli, A., Duckworth, S., Silva, J., & Yarmey, K. (2014). Capture All the URLs: First Steps in Web Archiving. Pennsylvania Libraries: Research & Practice, 2(2), 155–170. https://doi.org/10.5195/palrap.2014.67
Archive-It. (2014). About Us. Retrieved from https://archive-it.org/blog/learn-more/
Bragg, M., & Hanna, K. (2013). The Web Archiving Life Cycle Model. Retrieved from http://ait.blog.archive.org/files/2014/04/archiveit_life_cycle_model.pdf
Brügger, N. (2018). The archived web: Doing history in the digital age. Cambridge, MA: The MIT Press.
Di Cosmo, R., & Zacchiroli, S. (2017). Software Heritage: Why and How to Preserve Software Source Code. IPRES 2017 - 14th International Conference on Digital Preservation, 1–10. Retrieved from https://hal.archives-ouvertes.fr/hal-01590958
Dooley, J. & Bowers, K. (2018). Descriptive metadata for web archiving: Recommendations of the OCLC Research Library Partnership Web Archiving Metadata Working Group. Retrieved from https://www.oclc.org/content/dam/research/publications/2018/oclcresearch-wam-recommendations.pdf
Farrell, M., McCain, E., Praetzellis, M., Thomas, G., & Walker, P. (2018). Web Archiving in the United States: A 2017 Survey [Report]. Retrieved from https://osf.io/3QH6N/
Holzmann, H., Sperber, W., & Runnwerth, M. (2016). Archiving Software Surrogates on the Web for Future Reference. ArXiv:1702.01163 [Cs], 9819, 215–226. https://doi.org/10.1007/978-3-319-43997-6_17
Jackson, A. (2019). A New Release of Heritrix 3. Retrieved from https://netpreserveblog.wordpress.com/2019/02/19/a-new-release-of-heritrix-3/
Klein, M., & Van de Sompel, H. (2019). An Institutional Perspective to Rescue Scholarly Orphans. Retrieved from https://www.cni.org/topics/digital-preservation/an-institutional-perspective-to-rescue-scholarly-orphans
Klein, M., Sompel, H. V. de, Sanderson, R., Shankar, H., Balakireva, L., Zhou, K., & Tobin, R. (2014). Scholarly Context Not Found: One in Five Articles Suffers from Reference Rot. PLOS ONE, 9(12), e115253. https://doi.org/10.1371/journal.pone.0115253
Lohndorf, J. (2018). Archive-It Crawling Technology. Retrieved from http://support.archive-it.org/hc/en-us/articles/115001081186-Archive-It-Crawling-Technology
Memento Tracer. (2018). Memento Tracer Demo - GitHub. Retrieved from http://tracer.mementoweb.org/demos/github/
Software Heritage. (2019). You can “save code now”! Retrieved from https://www.softwareheritage.org/2019/01/10/save_code_now/