
Lab Notes: Web Archiving Tool Testing
We are excited to share with you a new series of Lab Notes detailing some of the more technical and hands-on aspects of our project. In a series of posts, I will be providing insights into my work using a few web archiving tools to capture git repositories, including Archive-It, Webrecorder, and Memento Tracer. I was previously the Web Archiving Fellow, and later Web Archiving Technician at NYARC so I am really excited to get the opportunity to experience web archiving workflows from a software preservation perspective. Today’s post will be on Archive-It, a subscription-based tool from the Internet Archive often used by GLAMs and governmental institutions for web archiving.
A little background
Software repositories held on git hosting platforms are composed of several key components. The core components are, of course, the source code and associated files that make up the repository’s directory, which can be thought of as a folder (or folders) holding all the files of code and documentation used for a project. We can access these files on a repository’s webpage simply by clicking and viewing the links for each file, or we can download the whole repository by clicking the "Download" button. If you’re interested in a little command line magic, you can use the git clone < repo-link > command to download a remote repository directly to your computer. Cloning provides the whole history of the source code, while the direct download method provides only the current version source code.
While the version controlled source code is the core of a git repository, there are many, many other interesting components that provide insights into the collaborative nature of a project and its development history over time (e.g. wikis, project boards, issue threads, etc). This content, unlike source code, is often contextual, living on the git hosting platform. We like to refer to this content as Scholarly Ephemera.
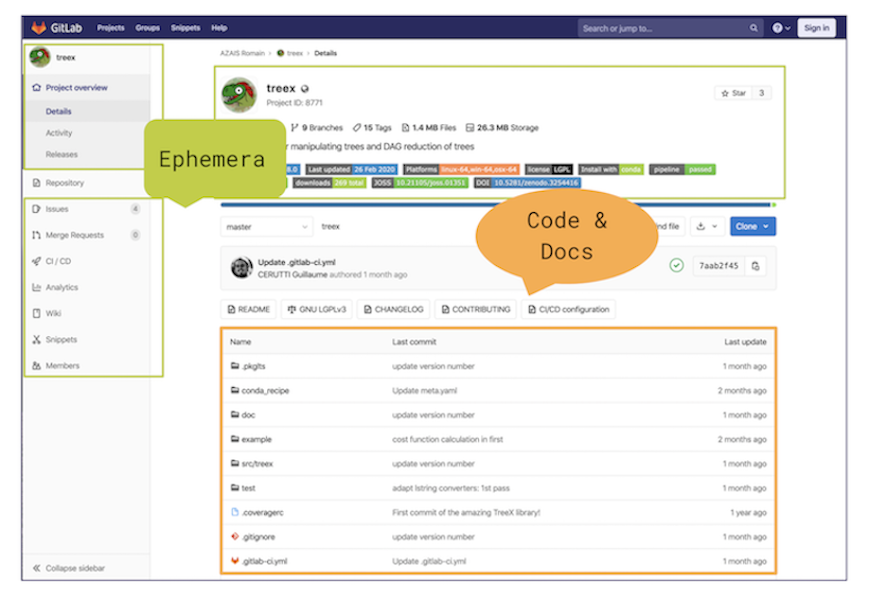
Research questions
Currently there is no one project that captures both source code and its associated scholarly ephemera. In light of this, we are asking if web archiving can be used to capture both of these. If so, what are the potential roadblocks or difficulties to this method? What are the constraints and considerations we need to keep in mind?
Procedure
To test some of these questions, I needed access to Archive-It. So I consulted with NYU’s web archivist Nicole Greenhouse to discuss some of my goals and objectives in detail and to schedule a few test crawls. Based on our conversations, I began to investigate the underlying HTML architecture of git hosting platforms and did some basic documentation/mapping regarding where code and ephemera were located on a repository’s page. This was a helpful exercise because it helped me to better understand consistent elements across repositories and to identify the specific content we were interested in capturing. I also documented how URLs were structured across repositories (e.g. domain, sub-directory, slug, etc ). This preliminary work was not only instructive, but also useful when it came to understanding the breadth of a repository, reviewing crawl reports and patching in any missing content.

After some background work and further weekly discussions, we decided to schedule two test crawls, one using Archive-It’s Brozzler crawler and the other using the Standard crawler (Heritrix and Umbra). For each test, we used the same four URLs, all which were taken from a list of research software repository links I scraped from the Journal of Open Source Software (JOSS). Each link served as a test for each git hosting platform (GitHub, GitLab, SourceForge, & BitBucket). Based on the results from the first two crawls, a third crawl using the Standard crawler and one GitHub URL was conducted.
Results & Observations
Test Crawl 1 - Brozzler & Standard crawler comparison
The first set of test crawls were conducted simultaneously so that I could compare the two crawling technologies offered by Archive-It. In reviewing the crawl reports and captures in Wayback, the first thing I noticed was the difference in sizes of each crawl. Specifically, the Brozzler crawl (3.9 GB) was much smaller than the Standard crawl (12.6 GB). An initial check of the eight archived sites (four for each crawler) showed that problems existed with the GitLab and BitBucket captures. Specifically, the archived Bitbucket page rendered as a white screen (see similar issue when using the “Save Page Now” feature), which may have to do with Javascript problems or, perhaps, documents in queue since BitBucket has the lowest document count by seed for both crawls. The GitLab capture was more complete, but there were still some rendering problems on the front page, so support tickets were submitted for these issues.
In comparison to the results for GitLab and BitBucket, the archived pages for GitHub and SourceForge for both crawlers were better, with the Standard crawler providing a more complete capture. Yet, due to the size difference mentioned above, it was necessary to see if the smaller Brozzler capture could be improved with QA. In turn, the Brozzler crawl was saved and I focused on QAing the GitHub repository, which was missing several components relating to source code and ephemera, including paginated content, commit messages, .zip & tar.gz files for the repository, and nested files. After two rounds of patch crawling with limited improvement, we decided to move forward with our best option so far — a Standard crawl on GitHub.
Test Crawl 2 - Standard crawl on one GitHub link
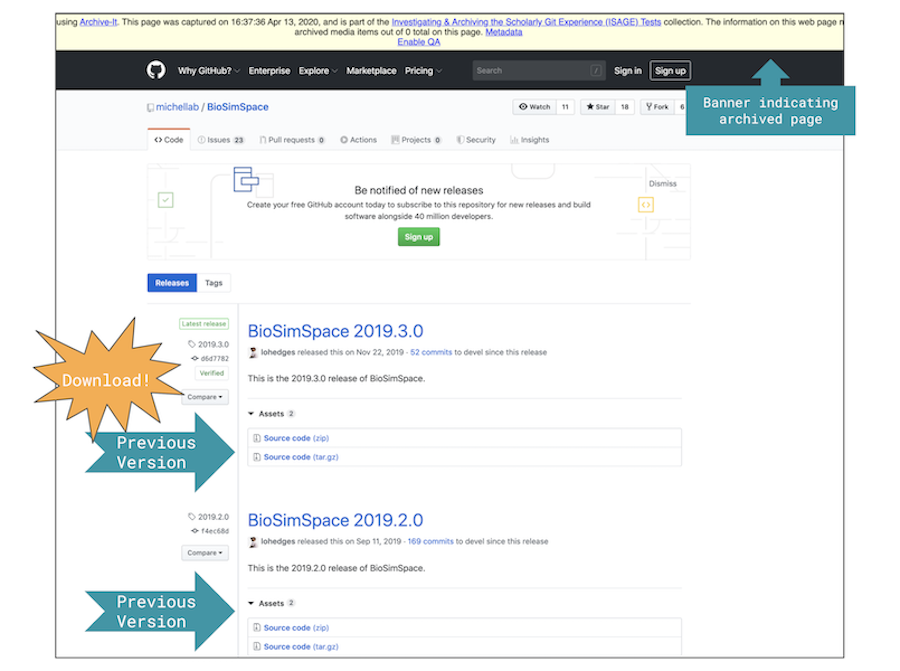
Although a bit on the large side for a single website (4.3 GB), crawling one GitHub repository with the Standard crawler resulted in a good capture (see archived site). In reviewing the crawl report, most of the documents came from the GitHub domain, many of which were similarly built according to the URL structure mentioned and pictured above. Regarding the software on the archived website, I was able to download a zip of the main directory and zip & tar.gz files of the five previous versions of the software (pictured). I was also able to access many of the files by navigating/browsing through the archived site. I noticed, however, that heavily nested content (e.g. a folder in a folder in a folder) did not capture. To determine which files were missing, I checked the repository file-by-file to get a better sense of the point at which nested content stopped being archived. This documentation confirmed that the crawler stopped three folders deep, which is somewhat problematic given this particular repository favored this type of deeply nested file organization.
As with the source code, a review of ephemera available on the archived site was also conducted. What was archived included the 23 issues that were open at the time of capture as well as 111 closed issues, and comments related to open and closed issues and their labels. Conversations and messages for pull requests were also captured, but individual commit messages for pull requests were not. Further, the first four pages of the commit messages on the development branch were archived and differences between new code and old code were visible. Older commit messages, however, were missing and would need to be patched in.
Screenshot of Archive-It crawl report using Standard crawler for single GitHub repository link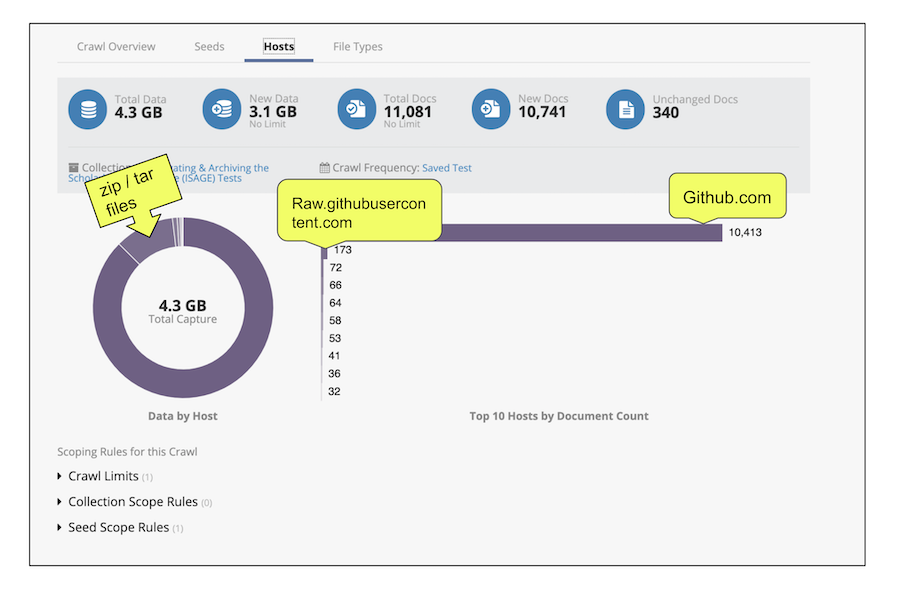
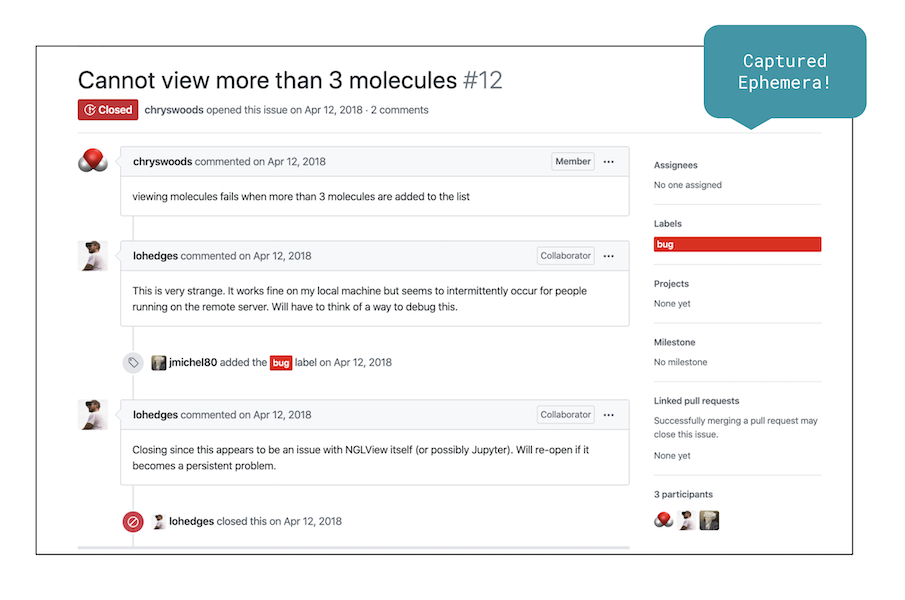
Challenges
Running test crawls, reviewing, and patching for a relatively small number of seed URLs took several weeks and a lot of conversation. Specifically, each crawl was set for three days and then additional time was needed to review crawl reports and archived web pages. Patch crawling was additionally time consuming. In Archive-It, patch crawling is done with the Wayback QA tool, which, in tandem with a user testing/clicking links, identifies missing content. While I was interested in patching the missing content identified in my file-by-file review, there were some challenges to this process. Specifically, when enabling QA mode for the GitHub repository, folders and files disappeared, then reappear when QA mode is turned off. A support ticket was submitted for this issue. Even without this particular issue, the iterative process of testing, reviewing, documenting, and testing again can be time intensive. Further, the use of these technologies to capture software and its ephemera, then make these assets accessible, is currently uncharted territory. Archive-It works very well for its stated purpose and is good at handling ephemera and zip files. The other types of captures we attempted, however, are currently more difficult due to patching limitations. This is not surprising as there is no established procedure in place and, as a result, a good deal of (informed) trial-and-error is necessary.